
Relational Database in the serverless era

Brief Introduction
It’s 2020. The architecture/stack of choice for many backend engineering teams these days is to use a combination of:
- Serverless functions (like AWS Lambda which runs code without us provisioning servers)
- NoSQL databases (like DynamoDB which is a fully managed, multi-region, multi-master, durable database).
Such modern stacks have enabled many startups to scale to the demands of millions of users without worrying about the provisioning costs and the high costs associated with scaling up hardware to support traditional technology architecture/stacks.
But in some situations, the benefits of using a relational database (SQL) when compared with a NoSQL database are too many, and hence a decision to move forward with the relational database makes complete sense.
But along with the benefits of a relational database that we had wished for, will also come the limitations and bottlenecks as we will see further in this article.
The connection limitation in Relational Databases
This is one of the biggest roadblocks that engineers run in to when their applications are hit with massive requests which require some database query/operation.
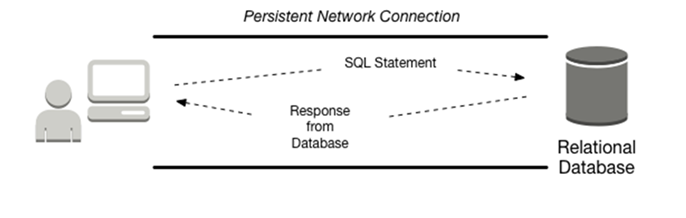
Q. But before that, what is this “connection” that we are talking about?
With a typical relational database engine such as MySQL, PostgreSQL or MSSQL, each client application instance is expected to establish a small number of connections to the engine and keep the connections open while the application is in use. This is referred to as a connection pool.
Then, when parts of the application need to interact with the database, then they borrow a connection from the pool, use it to make a query, and release the connection back to the pool. This makes efficient use of the connections and removes the overhead of setting up and tearing down connections as well as reduces the thrashing that results from creating and releasing the connection object resources.
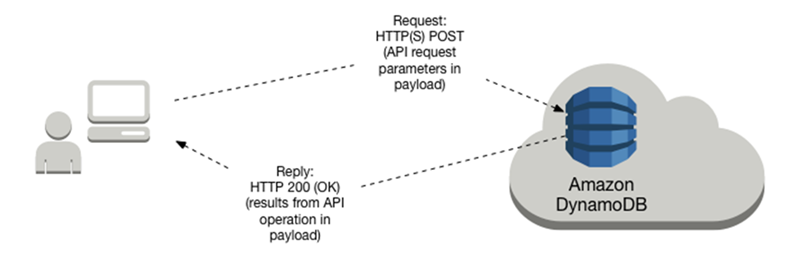
Q. How is connection different for a NoSQL database?
Let’s look at a specific NoSQL database while answering this question. We will choose DynamoDB since it’s already a popular NoSQL database choice.
With DynamoDB we no longer have persistent connections from the client to a database server. When we execute a Dynamo operation (query, scan, etc.) it’s an HTTP request/response which means the connection is established ad-hoc and lasts only the duration of the requests.
DynamoDB is a web service and it takes care of load balancing and routing to get us consistent performance regardless of scale. Hence, interactions with it are stateless, and we don’t need to bother about maintaining a connection pool.
Now that we understand what a connection means, let’s look at how many connections a relational database can support. We will look at a specific relational database, AWS Aurora to answer this.
| Instance Class | max_connections (Default Value) |
|---|---|
| db.t2.small | 45 |
| db.t2.medium | 90 |
| db.t3.small | 45 |
| db.t3.medium | 90 |
| db.r3.large | 1000 |
| … | … |
| db.r5.24xlarge | 7000 |
As we can see in this table, the default value for max_connections starts from 45 and goes up to 7,000. Of course this number can be configured to be higher, but it is generally set after considering the hardware specifications of the database server.
max_connections: The maximum permitted number of simultaneous client connections.
For example, if too many concurrent connections were established on a lower specification server, it will highly degrade the performance of the database server. This is because each connection consumes memory and CPU resources on the database server.
So from the above table, if our peak requirement was to support 80 concurrent connections, we might decide to choose a db.t2.medium database instance which has default max_connection value of 90.
Many database clients also provide configuration options where we can set this maximum connections option which we want our backend application to make.
Even in the scenarios where we decide to scale-out our backend application, we can allocate some percentage of max_connection to each backend instance, so that we can make sure that we never hit the max_connection limitation when combining connections across all backend instances.
How things get worse when using a serverless backend architecture.
Let us look at how things get complicated in this situation. Let’s assume we use AWS Lambda for our backend serverless functions. A typical architecture would involve an AWS API Gateway which would receive HTTP requests and in turn trigger the Lambda function via events.
Lambda functions can scale to tens of thousands of concurrent connections, meaning our database needs more resources to maintain connections instead of executing queries.
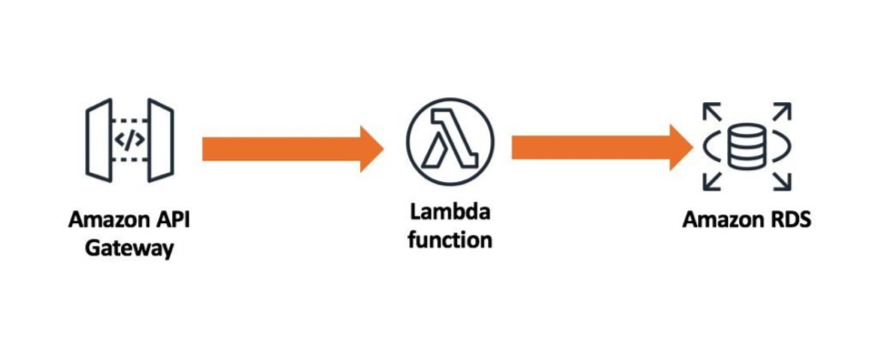
This design places high load on our backend relational database because Lambda can easily scale to tens of thousands of concurrent requests. In most cases, relational databases are not designed to accept the same number of concurrent connections.
To make things worse, Lambda instances spin up and die down quite frequently. So even a single running instance might lose it’s stateful information (like connection state) very quickly when compared with traditional backend application deployments on servers. This would lead to frequent open and close connection requests, which would cause additional strain on the database server’s performance.
Hence the two main visible issues when using serverless architecture for our backend applications is:
- Huge scale of concurrent Lambda connections to the database.
- High rate of open/close connection requests to the database.
Enter, RDS Proxy! 🎉
Amazon RDS Proxy is a fully managed, highly available database proxy for Amazon Relational Database Service (RDS) that makes applications more scalable, more resilient to database failures, and more secure.
AWS RDS Proxy acts as an intermediary between our application and an RDS database. RDS Proxy establishes and manages the necessary connection pools to our database so that our application creates fewer database connections.
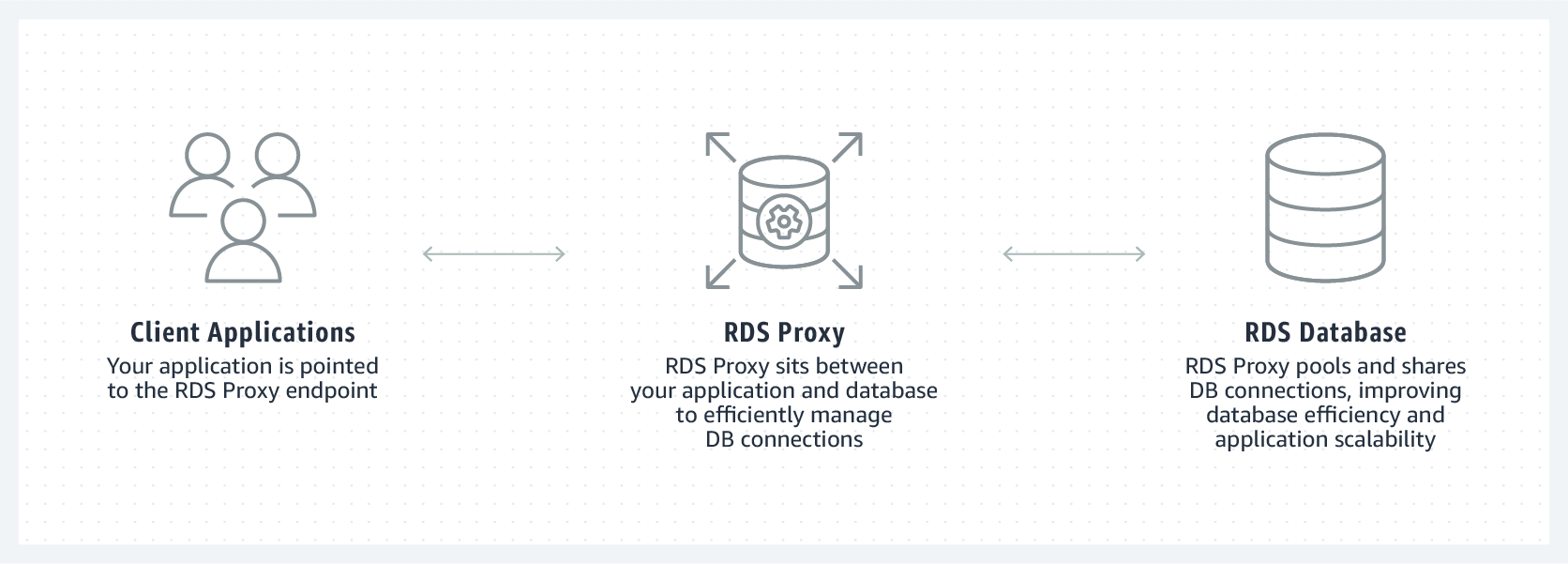
We can use RDS Proxy for any application that makes SQL calls to our database. But in the context of serverless, we focus on how this improves the Lambda experience. The proxy handles all database traffic that normally flows from our Lambda functions directly to the database.
- Problem: Huge scale of concurrent Lambda connections to the database.
Our Lambda functions interact with RDS Proxy instead of our database instance. It handles the connection pooling necessary for scaling many simultaneous connections created by concurrent Lambda functions. This allows our Lambda applications to reuse existing connections, rather than creating new connections for every function invocation.
- Problem: High rate of open/close connection requests to the database.
The RDS Proxy scales automatically so that our database instance needs less memory and CPU resources for connection management. It also uses warm connection pools to increase performance. With RDS Proxy, we no longer need code that handles cleaning up idle connections and managing connection pools. Our function code is cleaner, simpler, and easier to maintain.
Testing connections via RDS Proxy vs directly to RDS Aurora Database
We create a program that does the following:
- Opens multiple simultaneous connections to the Database.
- Keeps the connections open instead of closing them after the query.
- Checks how many such multiple connections are opened successfully and how many return errors.
The link to the go program is in this github repo.
Results from our tests
We perform the tests against db.t2.small database instance, which has a default max_connections value of 45.
We also keep the connections in our program open for 30 seconds before closing them (We decided to use this 30 seconds value as a simulation for a worse case backend).
| DB Type | Concurrent requests sent | Connection kept Open for | Error Count | Error Message | (suc_req / max_con) |
|---|---|---|---|---|---|
| RDS Aurora | 50 | 30 seconds | 10 | Error 1040: Too many connections | (40/45) = 0.9 |
| RDS Proxy | 50 | 30 seconds | 0 | - | (50/45) = 1.1 |
| RDS Proxy | 100 | 30 seconds | 0 | - | (100/45) = 2.2 |
| RDS Proxy | 200 | 30 seconds | 54 | Error 9501: Timed-out waiting to acquire database connection | (146/45) = 3.2 |
| RDS Proxy | 1000 | 30 seconds | 818 | Error 9501: Timed-out waiting to acquire database connection | (182/45) = 4.0 |
As seen above in the results table, when using the RDS Proxy, we can handle connection requests of around ~3 to 4 times more of what we would have been when compared with directly connecting to the RDS database instance.
Of course, these concurrent requests that we send will not be resolved simultaneously. The RDS Proxy just acts like a queue in this scenario and processes the concurrent requests in batches and resolves them. So the latency will be quite high for the requests that get processed in the later batches. But the good thing to notice here is that our requests failure from Error 1040: Too many connections type of errors will drop all together.
Another good thing to note is, in real life backend applications, the query time would generally be under 5 seconds, and we noticed that with such open connection time values, the RDS Proxy is able to successfully support open connections requests for up to 20 times the max_connections value! ⭐
RDS Proxy cost considerations
NOTE: According to AWS Blog articles, it is still recommended to use AWS RDS Cluster
readerendpoint directly from our backend applications when serving read queries instead of using an RDS Proxy. This is because thereaderendpoint automatically load-balances between all the read-replica instances.
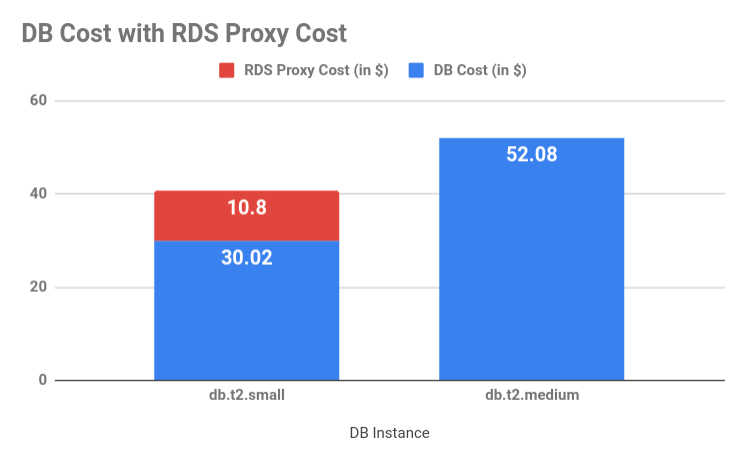
Let’s assume we have only one database instance in our cluster which serves both read and write queries. Our requests peak at let’s say ~100 concurrent write requests. Since we noticed above that we could serve a higher workload (~3 to 4 times) using RDS Proxy, let’s compare the costs for a db.t2.small instance and db.t2.medium instance.
| Instance Class | max_con | vCPU | DB Cost/month (in USD) | RDS Proxy Cost (in USD) |
|---|---|---|---|---|
| db.t2.small | 45 | 1 | 30.02 | (0.015 * 1 vCPU) * 24 * 30 = 10.8 |
| db.t2.medium | 90 | 2 | 52.08 | (0.015 * 2 vCPU) * 24 * 30 = 21.6 |
vCPU: The number of virtual central processing units (CPUs). A virtual CPU is a unit of capacity that you can use to compare DB instance classes. Instead of purchasing or leasing a particular processor to use for several months or years, you are renting capacity by the hour. Our goal is to make a consistent and specific amount of CPU capacity available, within the limits of the actual underlying hardware.
So if we use a combination of db.t2.small instance and RDS Proxy, it will cost us (30.02 + 10.8) = 40.82 USD per month. This is cheaper than using a db.t2.medium instance directly which would cost us 52.08 USD per month. This would let us save around 20% in database instance costs. 💸
Conclusion
RDS Proxy is definitely the go to solution when our backend applications are suffering with too many concurrent connections. This case is very common when using Serverless architecture for our backend applications due to the problems highlighted above.
Before thinking of changing our existing architecture and making it more complex like adding some message queues to have an event-driven type of architecture, so that we can handle multiple concurrent requests, we should definitely consider trying out the RDS Proxy. The best part is we can start using it with our existing application code without making any changes in our code. We just need to change the database endpoint.